Revolutionizing AI: Open-Source LLMs Outperform GPT-4
Written on
Chapter 1: The Rise of Open-Source LLMs
In the ongoing contest between open-source and proprietary AI solutions, a noteworthy shift has occurred. Sam Altman, during his visit to India, once asserted that while developers might attempt to replicate AI like ChatGPT, their efforts would ultimately fall short. However, recent developments have proven him incorrect.
A group of researchers has recently shared a preprint on ArXiv, detailing how a combination of various open-source large language models (LLMs) can be integrated to achieve exceptional results on multiple evaluation benchmarks, surpassing OpenAI's GPT-4 Omni. This innovative approach is known as the Mixture-of-Agents (MoA) model.
The findings revealed that the MoA model, composed entirely of open-source LLMs, achieved an impressive score of 65.1% on AlpacaEval 2.0, compared to GPT-4 Omni's score of 57.5%. This development is a testament to the evolving landscape of AI, which is becoming increasingly democratized, transparent, and collaborative.
The implications are significant: developers can now focus on leveraging the strengths of multiple LLMs rather than investing vast resources into training a single model, which could cost hundreds of millions of dollars. Instead, they can tap into the collective expertise of various models to produce superior outcomes.
This article delves into the intricacies of the Mixture-of-Agents model, examining its distinctions from the Mixture-of-Experts (MoE) model and assessing its performance across various configurations.
How the Mixture-of-Agents Model Operates
The Mixture-of-Agents (MoA) model capitalizes on a concept known as the Collaborativeness of LLMs. This concept suggests that an LLM can produce higher-quality outputs when it has access to responses generated by other LLMs, even if those models are not particularly strong on their own.
The MoA model is structured into multiple layers, with each layer comprising several LLM agents. Each agent receives input from all agents in the preceding layer and generates its output based on the collective information.
To illustrate, consider a scenario where the first layer of LLMs is presented with an input prompt. The responses they create are then forwarded to the agents in the subsequent layer. This process continues through each layer, with each layer refining the previous layer's outputs. Ultimately, the final layer consolidates all the responses, resulting in a single, high-quality output from the entire model.
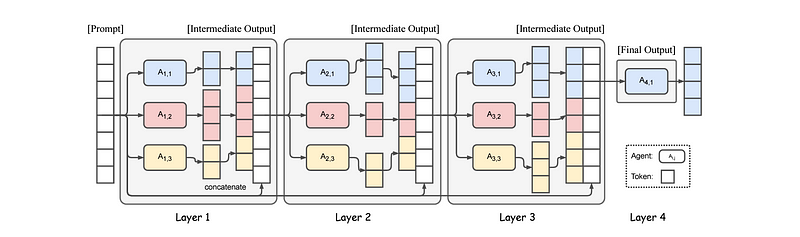
In a MoA model with l layers, where each layer i comprises n LLMs (denoted as A(i,n)), the output y(i) from the i-th layer for a given input prompt x(1) can be expressed mathematically.
The Role of LLM Agents in Mixture-of-Agents
Within a MoA layer, LLMs are categorized into two groups:
- Proposers: These LLMs generate diverse responses, which may not individually score highly on performance metrics.
- Aggregators: Their role is to combine the responses from the Proposers into a single, high-quality answer.
Notably, models such as Qwen1.5 and LLaMA-3 excelled in both roles, while others like WizardLM and Mixtral-8x22B performed better as Proposers.
Comparing MoA with Mixture-of-Experts
While the MoA model draws inspiration from the Mixture-of-Experts (MoE) model, there are key differences:
- The MoA employs full LLMs across layers rather than sub-networks.
- It aggregates outputs using prompting techniques instead of a Gating Network.
- It eliminates the need for fine-tuning and allows any LLM to participate without modifications.
Performance Metrics of the Mixture-of-Agents Model
The MoA model was constructed with several LLMs, including Qwen1.5–110B-Chat and LLaMA-3–70B-Instruct. It consisted of three layers featuring the same models, with Qwen1.5–110B-Chat serving as the aggregator in the final layer.
Three variants were evaluated against standard benchmarks: AlpacaEval 2.0, MT-Bench, and FLASK.
During the AlpacaEval 2.0 assessment, the MoA model achieved an 8.2% absolute improvement in the Length-Controlled Win metric over GPT-4o. Even the more economical MoA-Lite variant surpassed GPT-4o by 1.8%.
In this video, learn how to harness open-source AI models to outperform GPT-4, showcasing the potential of collaborative AI solutions.
Evaluating MoA on MT-Bench and FLASK
On the MT-Bench benchmark, which assesses models across three metrics, MoA and MoA-Lite demonstrated competitive performance relative to GPT-4o. The FLASK benchmark provided a detailed evaluation of model performance, where MoA excelled in several metrics, although its outputs were noted to be more verbose.
Cost and Computational Efficiency
In terms of cost efficiency, MoA-Lite matched GPT-4o while delivering superior response quality. Overall, MoA was identified as the optimal configuration for achieving high performance relative to cost.
This highlights a shift in AI development, emphasizing the potential of open-source models to deliver high-quality results without the exorbitant costs associated with proprietary models.
What are your thoughts on this innovative approach? How has your experience with open-source LLMs been in your projects? Share your insights in the comments below!
Further Reading
- Research paper titled ‘Mixture-of-Agents Enhances Large Language Model Capabilities’ in ArXiv
- Research paper titled ‘Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer’ in ArXiv
Stay Connected
If you'd like to follow my work, consider subscribing to my mailing lists:
- Subscribe to Dr. Ashish Bamania on Gumroad
- Byte Surgery | Ashish Bamania | Substack
- Ashish’s Substack | Ashish Bamania | Substack
Get notifications whenever I publish new content!
In this discussion, we explore the advantages and disadvantages of using open-source LLMs versus proprietary models like GPT-4, helping you make informed decisions for your AI projects.