Grasping With Common Sense: Leveraging LLMs for Robotics
Written on
Chapter 1: Understanding Grasping Challenges
Grasping and manipulation pose significant challenges within the field of robotics. It involves more than just determining where to place fingers on an object to ensure a secure hold; it also requires applying the right amount of force to lift the item without damaging it, while ensuring it can be used as intended. Additionally, grasping plays a vital role in gathering sensory information that helps identify an object's characteristics. With mobility largely addressed, mastering grasping and manipulation remains the key to achieving truly autonomous labor solutions.
Imagine instructing your humanoid robot to visit the grocery store with the command: “Check the avocados for ripeness and select one for guacamole.” This task encompasses various complexities: The quality of ripeness isn’t easily discernible solely from the avocado's exterior, as it might be with other fruits like strawberries or tomatoes; it necessitates tactile feedback. Selecting an avocado, particularly a ripe one, requires a gentle touch to avoid damage, unlike handling a more resilient item like a potato. Additionally, the phrase “for guacamole today” indicates a specific ripeness level distinct from that of an avocado intended for use three days later.
With the rise of large language models (LLMs) such as ChatGPT, this type of information can be extracted from a vast pool of internet sources. For instance, you could inquire about how to assess an avocado’s ripeness, what factors to consider while grasping it, how long it takes to mature, and what its texture would feel like at different stages of ripeness. The question then becomes: how can we utilize this knowledge in robotic manipulation? Our research, detailed in the paper “DeliGrasp: Inferring Object Mass, Friction, and Compliance with LLMs for Adaptive and Minimally Deforming Grasp Policies” [1], involved prompting ChatGPT to generate code for a responsive grasping controller that utilizes estimated physical properties. This method is illustrated in the accompanying figure and has been validated on twelve distinct delicate and deformable items, including food, toys, and other everyday objects, with varying masses and required lifting forces.
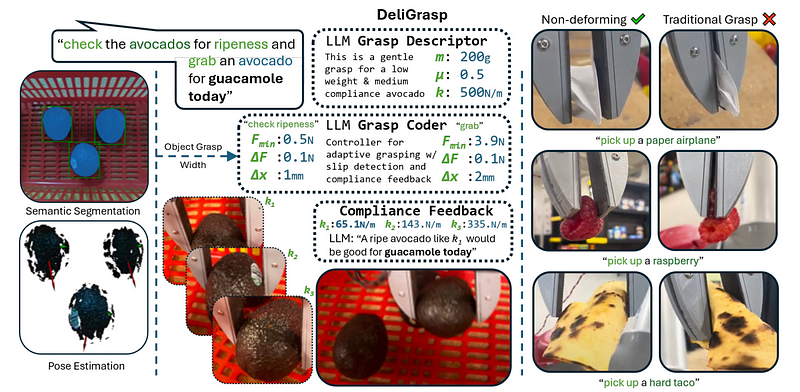
The system not only identifies the appropriate parameters for grasping fragile items like a paper airplane or a raspberry without crushing them, but it also effectively manages heavier objects without the risk of dropping them. It even allows for reasoning regarding relative properties, such as perceived stiffness, to determine which fruit is the ripest.
Section 1.1: Perception Pipeline
At the heart of DeliGrasp is an open-world localization pipeline that employs “OWL-ViT” (developed by Google), a vision-language model capable of localizing objects within an image without prior training, and “Segment Anything” (developed by Meta), a segmentation algorithm that isolates all pixels corresponding to an object when given an initial location from OWL-ViT. The resulting segmented point cloud undergoes principal component analysis to derive an initial grasping position.
Given a description of an object, such as “avocado” or “paper airplane,” this pipeline determines the object and a preliminary grasping location. The same description along with an associated action verb, like “pick,” serve as inputs to DeliGrasp, which produces a grasping policy: executable Python code that governs a gripper’s compliance, force, and aperture to execute the grasping skill for the specified object. This is achieved by supplying ChatGPT with a well-structured prompt that outlines the available application programming interface (API).
Section 1.2: Grasping Physics
A substantial amount of research has focused on developing grasping policies, ranging from generating a grasp pose based on an object's image to utilizing generative models that can incorporate force feedback. However, these models often lack transparency; we may not know how much pressure they exert on an object or how to control specific grasps. The physics of grasping, considering an object’s weight, friction coefficient, and spring constant, is relatively well understood.
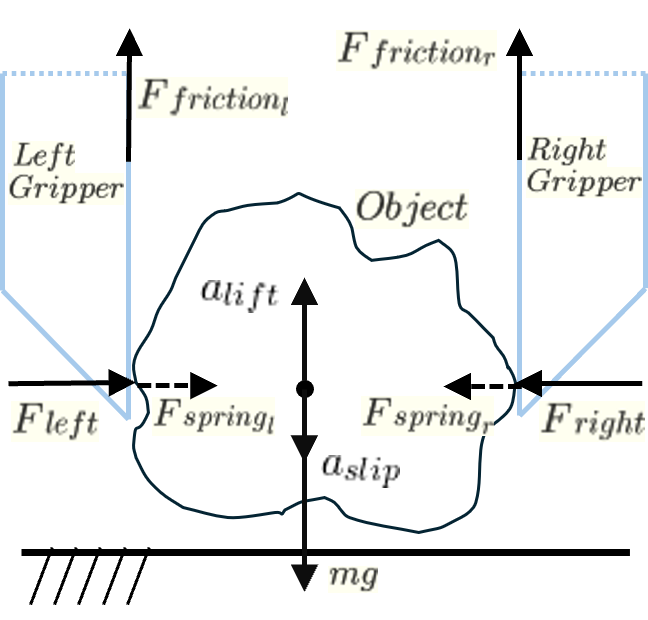
When grasping an object from the sides, only a portion of the force applied contributes to lifting it vertically. This portion depends on the friction coefficient, denoted as ? and described by Coulomb's friction principle:
F_friction_l = ? * F_left
To lift the object, the force exerted by friction must exceed the gravitational pull acting on it, represented as mg (where m is the object's mass and g is the acceleration due to gravity). Therefore, we can calculate the minimum grasping force required to overcome both gravity and slip:
F_min > mg/?
Assuming the object behaves like a spring with a spring constant k, an applied force will result in a displacement x:
F_spring_l = k * x
In the above illustration, x is shown by the dashed arrow, indicating the deformation of an object under pressure. A successful grasp must apply enough pressure such that the lateral friction surpasses the downward force. To achieve this, we employ an adaptive grasping controller that incrementally increases the force while reducing the grasping aperture.

We can utilize an LLM like GPT-4 to predict an object’s mass, friction coefficient, and expected spring constant. The same object description provided to OWL-ViT is also used here. Specifically, we ask the LLM to define and generate grasps using a dual-prompt approach: the initial prompt generates a structured description, while the subsequent prompt translates this into an executable Python grasp policy that adjusts the gripper's compliance, force, and aperture as outlined in Algorithm 1. Comprehensive prompts can be found in Appendices D and E of the paper.
Experiments
We evaluate DeliGrasp (DG) against three different grasping policies: fully closing the gripper, closing it to its output force limit (F.L.), and closing it to the visual object width (w) determined by our perception method. We also include an ablated version of DeliGrasp (DG-D) that directly generates the minimum force (F_min), force output change, and displacement (?x) without first assessing the object's physical properties.
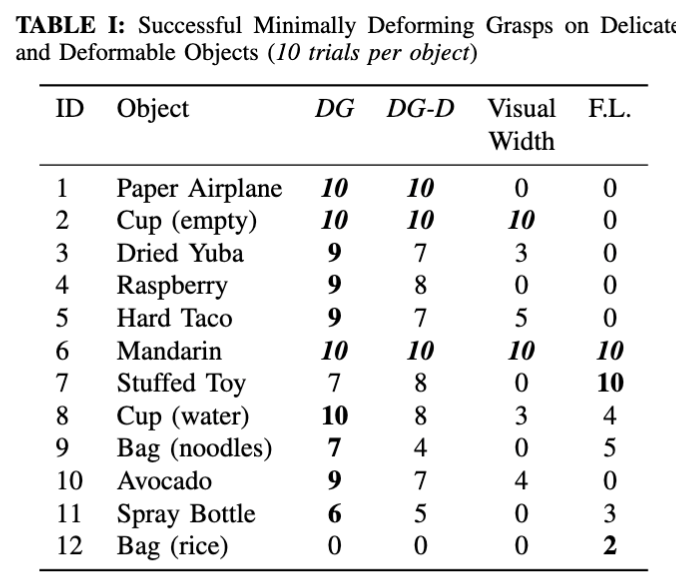
In our findings, the adaptive grasping policy demonstrated superior performance compared to traditional grasping methods in nearly all instances, except for a stuffed toy, where it tended to underestimate the necessary force. Notably, we also found that estimates of mass, friction coefficient, and spring constant derived from ChatGPT-4 significantly enhanced performance.
Section 1.3: Assessing Ripeness
Beyond utilizing extensive internet knowledge about various objects, we are also harnessing ChatGPT's common-sense reasoning capabilities. This includes making connections between an object's spring constant and its ripeness or suitability for specific recipes. We prompt the robot to record the spring constant of different items—k can be calculated from two consecutive force measurements using Algorithm 1—and suggest the best fruit option. This method proved effective for both avocados and tomatoes.
Summary: Integrating Common Sense into Grasping
We have demonstrated that ChatGPT-4 can effectively complement a principled approach to grasping. This method offers several advantages over models that generate trajectories directly from sensory data. First, our approach requires no additional training, as all necessary learning has already been accomplished when ChatGPT absorbed relevant information from the internet. Second, it is inherently explainable, allowing users to understand the reasoning behind a robot's actions. For instance, ChatGPT can clarify that it associates the lowest spring constant with the ripest fruit and can further elucidate concepts such as the spring constant or the mechanics of grasping.
References
[1] Xie, W., Lavering, J. and Correll, N., 2024. DeliGrasp: Inferring Object Mass, Friction, and Compliance with LLMs for Adaptive and Minimally Deforming Grasp Policies. arXiv preprint arXiv:2403.07832.